현업에서 공지사항에 이모지를 작성할 수 있게 해달라는 요청이 왔습니다! 하지면 당행 내에 이모지를 DB에 저장하여 사용한 업무는 전무했습니다…
오라클에 이모지(Emoji)를 저장할 수 있을까?
현재까지 제가 확인한 정답은 '아니요' 입니다.
이모티콘(emoji) 는 4byte 에 해당하는 유니코드로 오라클 charset UTF-8 (3byte) 에서는 호환되지 않아 [???] 로 저장됩니다. 따라서 오라클에서는 이모지 저장이 불가능합니다. 회사 내에 이모지 변환 규약을 새로 설정하던지, mySQL 데이터 베이스를 사용해야 합니다! 현재는 화면 단에서 원천적으로 이모지 입력이 불가능하게 제어해두었습니다.
mysql charset에는 utf8mb4라는 charset을 지원하기 때문입니다. charset이란 문자가 어떠한 ‘코드’로 저장될지 규칙을 정하는 것을 의미합니다. 기존에 사용하던 ‘utf_’로 시작되는 charset은 가변3바이트를 사용합니다. 반면 ‘utfmb4_’로 시작되는 charset은 한문자를 인코딩하는데 4바이트를 사용합니다. 실제로 이모지는 4 byte를 필요로 하기 때문에 utf8mb4라는 charset을 사용하면 이모지를 저장할 수 있게 됩니다.
중요한 핵심 내용만 참조해 보자면, 아래와 같이 정상응답이건 에러응답이건 모든 요청에 공통으로 보낼 형식을 만들어 줍니다.
@Getter
public class ApiResponseDto<T> {
private boolean success;
private T response;
private ErrorResponse error;
@Builder
private ApiResponseDto(boolean success, T response, ErrorResponse error) {
this.success = success;
this.response = response;
this.error = error;
}
}
그리고 요청 결과에 따라 알맞는 데이터를 넣어 ApiResponseDto를 생성할 static method를 만들어, 아래와 같이 사용할 수 있습니다.
① 정상 : TRUE + Response 조립 ② 에러 : FALSE + Error Response 조립 ③ 에러지만 정상데이터 요청 : FALSE + Response + Error Response 조립
public class ResponseUtils {
// 요청 성공인 경우
public static <T> ApiResponseDto<T> ok(T response) {
return ApiResponseDto.<T>builder()
.success(true)
.response(response)
.build();
}
// 에러 발생한 경우
public static <T> ApiResponseDto<T> error(ErrorResponse response) {
return ApiResponseDto.<T>builder()
.success(false)
.error(response)
.build();
}
// 요청 실패이지만 데이터를 내려줘야 할 경우
public static <T> ApiResponseDto<T> error(T response, ErrorResponse errorResponse) {
return ApiResponseDto.<T>builder()
.success(false)
.response(response)
.error(errorResponse)
.build();
}
}
ResponseEntity 대신 ApiResponseDto를 사용하는 이유는?
HttpStatus, HttpHeaders, HttpBody 데이터를 갖는 ResponseEntity 클래스를 활용할 수 있습니다. 다양한 생성자가 있기 때문에 응답 데이터가 없는 케이스, Http Header를 반환하지 않는 케이스 등 상황에 맞는 생성자를 선택해 사용할 수 있습니다. 하지만 예외가 발생하는 경우 응답 body로 plain/text가 전달됩니다. 즉 예외가 발생했을 때, 성공했을 때 응답의 모양이 달라지기 때문에 경우에 따라 응답 데이터의 형식이 달라지는 경우 상황에 따라 가변적으로 사용하기 어렵니다.
그래서 성공했을 때 형식과 실패했을 때 응답형식을 항상 json으로 통일시키기 위해 ApiResponseDto를 사용한 것입니다.
① @ExceptionHandler : Controller Level ② @ControllerAdvice : Global Level ③ try ~ catch문 : Method Level
@ExceptionHandler : 컨트롤러단에서 처리
@ExceptionHandler는 Controller계층에서 발생하는 에러를 잡아서 메서드로 처리해주는 기능입니다.
Service, Repository에서 발생하는 에러는 제외합니다.
@RestController
@RequestMapping("/person")
public class PersonController {
@GetMapping
public String test(){
return "test";
}
@GetMapping("/exception")
public String exception1(){
throw new NullPointerException();
}
@GetMapping("/exception2")
public String exception2(){
throw new ClassCastException();
}
@ExceptionHandler({NullPointerException.class, ClassCastException.class})
public String handle(Exception ex){
return "Exception Handle!!!";
}
}
@ControllerAdvice : 전역에서 처리
@ControllerAdvice는 @Controller와 handler에서 발생하는 에러들을 모두 잡아줍니다.
@ControllerAdvice안에서 @ExceptionHandler를 사용하여 에러를 잡을 수 있습니다.
@RestControllerAdvice
public class ControllerSupport {
@ExceptionHandler({NullPointerException.class, ClassCastException.class})
public String handle(Exception ex) {
return "Exception Handle!!!";
}
}
@RestController
@RequestMapping("/school")
public class SchoolController {
@GetMapping
public String test(){
return "test";
}
@GetMapping("/exception")
public String exception1(){
throw new NullPointerException();
}
@GetMapping("/exception2")
public String exception2(){
throw new ClassCastException();
}
}
@RestController
@RequestMapping("/person")
public class PersonController {
@GetMapping
public String test(){
return "test";
}
@GetMapping("/exception")
public String exception1(){
throw new NullPointerException();
}
@GetMapping("/exception2")
public String exception2(){
throw new ClassCastException();
}
}
try ~ catch문 : 메서드 단위에서 처리
throw 키워드를 사용하여 프로그래머가 고의로 예외를 발생시킬수 있습니다.
try 문에서 Exception 예외가 발생할 경우 catch (Exception e) 로 빠져서 그 안의 실행문을 실행한다.
마지막 finally블럭은 try-catch문과 함께 예외발생 여부과 관계없이 "항상. 무조건" 실행되어야할 코드를 적는다.
예외 발생시 try → catch → finally 순으로, 발생 하지 않은 경우 try → finally 순으로 실행됩니다.
스프링 Exception 전략
아래 글에 효과적인 Exception 전략 내용이 인상적이라 중요한 핵심 내용 몇가지만 요약해보겠습니다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ErrorResponse {
private String message;
private int status;
private List<FieldError> errors;
private String code;
...
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public static class FieldError {
private String field;
private String value;
private String reason;
...
}
}
이처럼 통일된 POJO 객체로 Error Response를 관리하면, 리턴 타입을 ResponseEntity<ErrorResponse>으로 반환하여 무슨 데이터가 어떻게 있는지 명확하게 추론하기 쉽도록 구성할 수 있습니다.
@ExceptionHandler(MethodArgumentNotValidException.class)
protected ResponseEntity<ErrorResponse> handleMethodArgumentNotValidException(MethodArgumentNotValidException e) {
log.error("handleMethodArgumentNotValidException", e);
final ErrorResponse response = ErrorResponse.of(ErrorCode.INVALID_INPUT_VALUE, e.getBindingResult());
return new ResponseEntity<>(response, HttpStatus.BAD_REQUEST);
}
@ControllerAdvice로 모든 예외를 핸들링
스프링 및 라이브러리 등 자체적으로 발생하는 예외는 @ExceptionHandler 으로 추가해서 적절한 Error Response를 만들고 비즈니스 요구사항에 예외일 경우 BusinessException 으로 통일성 있게 처리하는 것이 좋습니다.
@ControllerAdvice
@Slf4j
public class GlobalExceptionHandler {
/**
* javax.validation.Valid or @Validated 으로 binding error 발생시
* HttpMessageConverter 에서 등록한 HttpMessageConverter binding 못할경우 발생
* 주로 @RequestBody, @RequestPart 어노테이션에서 발생
*/
@ExceptionHandler(MethodArgumentNotValidException.class)
protected ResponseEntity<ErrorResponse> handleMethodArgumentNotValidException(MethodArgumentNotValidException e) {
log.error("handleMethodArgumentNotValidException", e);
final ErrorResponse response = ErrorResponse.of(ErrorCode.INVALID_INPUT_VALUE, e.getBindingResult());
return new ResponseEntity<>(response, HttpStatus.BAD_REQUEST);
}
/**
* @ModelAttribut 으로 binding error 발생시 BindException 발생
* ref https://docs.spring.io/spring/docs/current/spring-framework-reference/web.html#mvc-ann-modelattrib-method-args
*/
@ExceptionHandler(BindException.class)
protected ResponseEntity<ErrorResponse> handleBindException(BindException e) {
log.error("handleBindException", e);
final ErrorResponse response = ErrorResponse.of(ErrorCode.INVALID_INPUT_VALUE, e.getBindingResult());
return new ResponseEntity<>(response, HttpStatus.BAD_REQUEST);
}
/**
* enum type 일치하지 않아 binding 못할 경우 발생
* 주로 @RequestParam enum으로 binding 못했을 경우 발생
*/
@ExceptionHandler(MethodArgumentTypeMismatchException.class)
protected ResponseEntity<ErrorResponse> handleMethodArgumentTypeMismatchException(MethodArgumentTypeMismatchException e) {
log.error("handleMethodArgumentTypeMismatchException", e);
final ErrorResponse response = ErrorResponse.of(e);
return new ResponseEntity<>(response, HttpStatus.BAD_REQUEST);
}
/**
* 지원하지 않은 HTTP method 호출 할 경우 발생
*/
@ExceptionHandler(HttpRequestMethodNotSupportedException.class)
protected ResponseEntity<ErrorResponse> handleHttpRequestMethodNotSupportedException(HttpRequestMethodNotSupportedException e) {
log.error("handleHttpRequestMethodNotSupportedException", e);
final ErrorResponse response = ErrorResponse.of(ErrorCode.METHOD_NOT_ALLOWED);
return new ResponseEntity<>(response, HttpStatus.METHOD_NOT_ALLOWED);
}
/**
* Authentication 객체가 필요한 권한을 보유하지 않은 경우 발생
*/
@ExceptionHandler(AccessDeniedException.class)
protected ResponseEntity<ErrorResponse> handleAccessDeniedException(AccessDeniedException e) {
log.error("handleAccessDeniedException", e);
final ErrorResponse response = ErrorResponse.of(ErrorCode.HANDLE_ACCESS_DENIED);
return new ResponseEntity<>(response, HttpStatus.valueOf(ErrorCode.HANDLE_ACCESS_DENIED.getStatus()));
}
/**
* 비즈니스 요규사항에 따른 Exception
*/
@ExceptionHandler(BusinessException.class)
protected ResponseEntity<ErrorResponse> handleBusinessException(final BusinessException e) {
log.error("handleEntityNotFoundException", e);
final ErrorCode errorCode = e.getErrorCode();
final ErrorResponse response = ErrorResponse.of(errorCode);
return new ResponseEntity<>(response, HttpStatus.valueOf(errorCode.getStatus()));
}
/**
* 개발자가 직접 핸들링해서 다른 예외로 던지지 않으면 모두 이곳으로 모인다.
*/
@ExceptionHandler(Exception.class)
protected ResponseEntity<ErrorResponse> handleException(Exception e) {
log.error("handleEntityNotFoundException", e);
final ErrorResponse response = ErrorResponse.of(ErrorCode.INTERNAL_SERVER_ERROR);
return new ResponseEntity<>(response, HttpStatus.INTERNAL_SERVER_ERROR);
}
}
컨트롤러 예외 처리
컨트롤러에서 모든 요청에 대한 값 검증을 진행하고 이상이 없을 시에 서비스 레이어를 호출해야 합니다. 위에서도 언급했듯이 잘못된 값이 있으면 서비스 레이어에서 정상적인 작업을 진행하기 어렵습니다. 무엇보다 컨트롤러의 책임을 다하고 있지 않으면 그 책임은 자연스럽게 다른 레이어로 전해지게 되며 이렇게 넘겨받은 책임을 처리하는데 큰 비용과 유지보수 하기 어려워질 수밖에 없습니다.
@RestController
@RequestMapping("/members")
public class MemberApi {
private final MemberSignUpService memberSignUpService;
@PostMapping
public MemberResponse create(@RequestBody @Valid final SignUpRequest dto) {
final Member member = memberSignUpService.doSignUp(dto);
return new MemberResponse(member);
}
}
Reuqest Body @Valid 어노테이션으로 예외를 발생시킬 수 있습니다. 이 예외는 @ControllerAdvice에서 적절하게 핸들링 됩니다.
public class SignUpRequest {
@Valid private Email email;
@Valid private Name name;
}
public class Name {
@NotEmpty private String first;
private String middle;
@NotEmpty private String last;
}
public class Email {
@javax.validation.constraints.Email
private String value;
}
Try Catch 전략
Checked Exception이 발생하면 더 구체적인 Unchecked Exception을 발생시키고 예외에 대한 메시지를 명확하게 전달하는 것이 효과적입니다. Checked Exception과 Unchecked Exception :
꼭 알아야 하는 트랜잭션의 특징 하나만 기억하자면, 한 거래(트랜잭션) 내에 작업 전체가 실패하거나 성공하는 하나의 작업으로 묶는다는 점입니다.
실패한 트랜잭션 : A고객의 계좌이체
① 출금 계좌 목록 SELECT → 성공 ② 출금 계좌 잔액 UPDATE → 성공 ③ 출금 거래 기록 INSERT → 성공 ④ 입금 거래 처리(당행이체/타행이체) → 실패 : 작업 전체 ROLLBACK ⑤ 입금 거래 기록 INSERT
성공한 트랜잭션 : B고객의 계좌이체
① 출금 계좌 목록 SELECT → 성공 ② 출금 계좌 잔액 UPDATE → 성공 ③ 출금 거래 기록 INSERT → 성공 ④ 입금 거래 처리(당행이체/타행이체) → 성공 ⑤ 입금 거래 기록 INSERT → 성공 : 작업 전체 COMMIT
만약 출금 거래까지만 INSERT가 되고 입금 거래내역이 INSERT 되지 않는다면, 거래 내역의 부정확한 데이터들이 생겨나겠죠? 그래서 한 거래 내에서는 1개의 작업이라도 실패하면 전체 DB를 다 Rollback 처리하고, 모든 작업이 성공해야만 DB Commit을 진행해야 합니다.
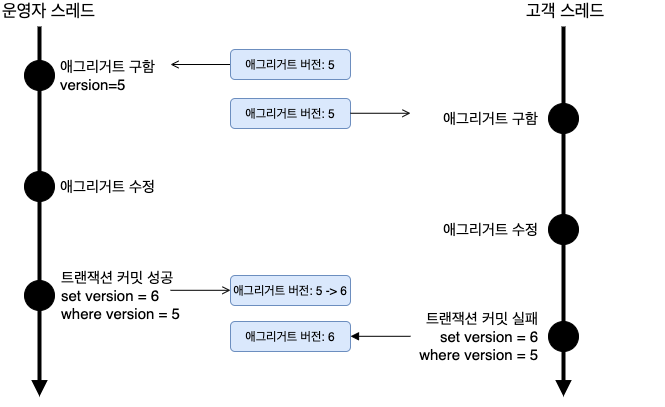
만약 계좌이체 진행 중에 다른 스레드 요청이 들어오면 어떻게 될까?
A고객의 거래이체 트랜잭션이 끝나기 전에 B고객의 계좌이체 요청이 들어온 경우를 가정해 봅시다. A고객의 요청이 먼저 들어왔으니, B의 요청은 A가 끝날 때까지 대기해야 할까요? 아닙니다! 보통 동시에 요청이 들어오면, 각 트랜젝션은 동시에 처리됩니다.
하지만 트랜잭션이 동시에 처리 가능한 개수를 지정해두지 않으면 서버가 과부하 걸려 죽을 수밖에 없겠죠? 그래서 스프링을 생각해 보면, 톰캣 WAS 내에 구현된 스레드풀에 의해서 요청의 갯수가 제어됩니다. Default로 200개의 쓰레드 요청을 허용한다고 하니 아래 내용을 참고해 보세요!
동시에 발생한 거래 - A고객 : 2번 계좌에서 1번 계좌로 100원 입금 (1번 : 500원 → 600원 / 2번 : 1000원 → 900원 ) - B고객 : 1번 계좌에서 2번 계좌로 800원 입금 (1번 : 500원 → -300원 / 2번 : 1000원 → 1800원 )
과연 두 거래가 동시에 처리된다면, DB 내에 거래 잔액이 어떻게 될까요?
1번계좌
2번계좌
최근 거래 후 잔액
500원
1000원
A고객, B고객 잔액조회 (동시)
500원
1000원
A고객 출금 (2번 → 1번 : 100원)
500 + 100 = 600원
1000 - 100 = 900원
B고객 출금 (1번 → 2번 : 800원)
500 - 800 = -300원
1000 + 800 = 1800원
C고객 잔액조회
-300원
1800원
C고객이 잔액을 조회했을 때, B고객이 출금한 이후에 잔액만 볼 수 있겠죠? A고객이 계좌이체한 내역은 DB에 남아있지 않겠죠? 그래서 필요한 것이 바로 DB Lock입니다!
DB Lock이 뭘까?
DB Lock이란 데이터베이스는 여러 사용자들이 같은 데이터를 동시에 접근하는 상황에서, 데이터가 어긋나지 않도록 DB를 보호하는 방법입니다!
위의 상황에서 A와 B고객이 똑같은 데이터를 읽어가는 일이 발생하지 않도록 계좌 잔액이 기록된 테이블에 Lock을 걸어둔다면, 두 트랜젝션이 동시에 들어와도 0.00001초라도 먼저 요청한 고객이 테이블을 읽고 있다면, 다른 요청이 들어와도 테이블 SELECT가 되지 않아 잔액이 틀어지지 않게 되는 거죠!
DB Lock을 설정할 수 있는 범위는?
일반적으로는 Table Lock과 Row Lock을 주로 접하게 됩니다. 데이터베이스 전체, 파일, 블록, 컬럼 단위로도 Lock을 걸 수 있지만 실무에서 본 기억은 없습니다.
테이블 락(Table Lock)
테이블 수준의 Lock은 테이블을 기준으로 Lock을 설정합니다.
이는 테이블의 모든 행을 업데이트 하는 등의 전체 테이블에 영향을 주는 변경을 수행할 때 유용합니다.
주로 DDL(create, alter, drop 등) 구문과 함께 사용되며 DDL Lock이라고도 합니다.
DB Lock은 크게 공유(Shared) Lock과 베타(Exclusive), 업데이트(Update) Lock있습니다.
공유락(Shared Lock) : 읽기 O , 쓰기 X ① 공유 Lock은 데이터를 읽을 때 사용되며, Read Lock이라고도 불립니다. ② 공유 Lock은 공유 Lock 끼리는 동시에 접근이 가능합니다. 즉, 하나의 데이터를 읽는 것은 여러 사용자가 동시에 할 수 있다라는 것입니다. ③ 공유 Lock이 설정된 데이터에 베타 Lock을 사용할 수는 없습니다.
베타락(Exclusive Lock) : 읽기 X , 쓰기 X ① 베타 Lock은 데이터를 변경하고자 할 때 사용되며 Write Lock이라고도 불립니다. ② 베타 Lock은 트랜잭션이 완료될 때까지 유지됩니다. 베타락은 Lock이 해제될 때까지 다른 트랜잭션(읽기 포함)은 해당 리소스에 접근할 수 없습니다. ③ 베타 Lock이 걸려있다면 다른 트랜잭션은 공유 락, 배타 락 둘 다 획득 할 수 없습니다. 업데이트락(Update Lock) U-Lock 잠금이 걸려 있어도 S-Lock만은 걸 수 있다 정도로 알면 될것 같습니다. https://resisa.tistory.com/m/184
실무환경에서는 조회 속도 향상을 위해 PK로 잡혀있지 않은 컬럼에 INDEX를 걸어둔 것을 많이 볼 수 있는대요~ 과연 인덱스는 어떤 기준에 따라 사용하는 것이 알맞을지 한 번 알아보도록 하겠습니다!
인덱스를 결정하는 기준은?
인덱스를 결정할 때에는 인덱스를 통해 읽어들이는 레코드 수가 얼마나 되는지를 고려해야합니다.
총 10만건의 데이터가 존재하는 경우, 특정 인덱스를 활용한다면 5만건의 데이터가 조회된다고 가정해봅시다. 이러한 인덱스는 10만건의 데이터를 전체 스캔하는 경우와 비교했을때 크게 성능이 향상된 것이라 볼 수 있을까요? 대답은 '아니다!' 입니다. 굳이 인덱스를 걸지 않아도 Table Full Scan로 조회하는 것이 더 이득일 수 있기 때문입니다.
따라서, 인덱스를 잡을 때 일반적으로 전체 레코드 갯수의 20% 미만의 레코드만 읽어올 수 있다면 효율적인 인덱스라고 볼 수 있다고 합니다.
이러한 점을 고려해서, 인덱싱 전략으로 크게 아래 네 가지 기준이 있다고 합니다.
① 카디널리티 (Cardinality)가 높은가? ② 선택도 (Selectivity)가 낮은가? ③ 중복도가 낮은가? ④ 활용도가 높은가?
자세한 내용은 아래에서 하나씩 차근차근 다뤄보도록 하겠습니다.
카디널리티(Cardinality) : 적당히 높을수록 Good!
카디널리티(Cardinality)란 특정 데이터 집합의 유니크한 값의 개수입니다.
- 만약, 5개의 부서만 존재한다면? 해당 컬럼의 'Cardinality = 5'가 됩니다. - 성별의 경우에는 '남', '여' 두 가지 값이 존재하기 때문에 'Cardinality = 2'가 됩니다.
인덱싱 전략에서 Cardinality가 높은 컬럼에 인덱스를 걸어야 합니다. Cardinality가 낮다면, 읽어야할 레코드의 수가 그만큼 많아지기 때문입니다.
하지만 카디널리티는 데이터의 특성에 따라 상대적인 수치입니다.
만약 직원들의 개인정보가 담겨있는 '직원 테이블(emp_tbl)'이 있다고 가정해봅시다.
- '직원번호'는 중복값이 존재하지 않기 때문에 Cardinality가 높다고 할 수 있습니다. - '부서코드'는 중복도가 상대적으로 높기 때문에 '직원번호'에 비해 Cardinality가 낮다고 할 수 있습니다.
선택도 (Selectivity) : 적당히 낮을수록 Good!
선택도(Selectivity)는 데이터 집합에서 특정 값을 얼마나 잘 골라낼 수 있는지에 대한 지표라 볼 수 있습니다.
자료를 찾아보면, 혹자는 선택도가 높을수록 좋다고 하고, 혹자는 선택도가 낮을수록 좋다고 하는데 과연 무엇이 맞는 걸까요?
선택도 = 카디널리티 / 총 레코드 수 * 100 (%)
선택도를 구하는 공식입니다. 카디널리티는 앞에서 알아봤듯 중복되지 않는 유니크한 값의 갯수입니다.
선택도가 100%이라면, [유니크한 값의 갯수 = 총 레코드의 갯수] 라는 뜻입니다. 즉, 테이터 내에 중복되는 값이 1개도 없다는 의미겠죠? 만약 선택도가 100%인 컬럼에 인덱스를 걸게 되면, 읽어들어 올 수 5있는 데이터가 1개 뿐입니다. 이런 데이터는 PK로 잡는게 맞겠죠? 따라서 선택도가 100%인 컬럼은 PK로 잡고, 선택도가 20% 미만이 되는 컬럼을 Index로 잡는 것이 효율적인 것으로 판단됩니다.
반면 선택도가 너무 낮으면, 전체 테이블을 Full Scan하는 것과 효율의 차이가 없습니다. 적당히 선택도가 낮은(10~30%) 데이터를 인덱스로 잡아야, 걸러지는 양이 많아져 쓸데없는 데이터를 읽지 않을 수 있어 성능적으로 이득을 볼 수 있습니다.
- MAX(선택도) = 100% - 선택도가 높다 : 한 컬럼이 갖고 있는 값 하나로 적은 레코드가 찾아진다. - 선택도가 낮다 : 한 컬럼이 갖고 있는 값 하나로 많은 레코드가 찾아진다.
중복도
중복도는 카디널리티와 비슷한 개념이기 때문에 간단하게 설명하고 넘어가도록 하겠습니다.
중복도가 낮을수록 인덱스로 설정하기 좋은 컬럼이라고 볼 수 있습니다. 중복도가 낮을수록 조건절에서 찾아지는 레코드가 적기 때문에, 탐색할 범위가 줄어들기 때문입니다.
활용도
활용도 또한 너무 당연한 개념이기 때문에 설명은 생략하겠습니다. 활용도가 적은 컬럼이라면 굳이 인덱스를 잡아서 물리적 공간을 차지할 필요가 없겠죠?
파티션 테이블(Partition Table)이란 사용자가 정의한 기준에 따라 데이터를 분할하여 저장해놓은 테이블입니다. 논리적인 1개의 테이블에 대해서, 여러개의 파티션 테이블을 분할하여 물리적으로 다른 공간에 저장하는 것이죠!
이때, 실제 데이터가 물리적으로 저장되는 곳은 Partition으로 나누어진 Tablespace입니다. 즉, 파티션되지 않은 테이블은 테이블과 저장영역이 1:1 관계지만, 파티션된 테이블일 때는 1:M 관계가 됩니다.
파티션 테이블을 사용하는 이유는?
일반적으로는 오랜 기간 동안 쌓인 데이터를 효율적으로 관리하고 성능저하를 방지하기 위한 용도로 파티션 테이블을 사용합니다. 서로 다른 파티션에 데이터를 저장함으로써 물리적 공간이 분할되어 노드 간의 디스크 경합을 최소화할 수 있다는 장점이 있어 많이 사용합니다!
또한 인덱스를 이용한 Random 액세스 방식은 데이터의 양이 일정 수준을 넘어가는 순간 Full Table Scan보다 오히려 성능이 나빠진다고 합니다. 그렇다고 대용량 데이터 테이블을 Full Scan 하는 것은 매우 비효율적이기 때문에, 테이블을 파티션 단위로 나누어 Full Table Scan이라 하더라도 일부 세그먼트만 읽고 작업을 마칠 수 있게 합니다.
실무 사례 : 최종 로그인 기록 조회 시간 단축
최근 고객의 로그인 실적에 따라 금리 우대를 제공하는 상품이 개발되었습니다. 그래서 고객의 월별 최종로그인 일자를 수신팀에 제공해야 하는 일이 생겼습니다.
하지만 고객의 최종 로그인 정보가 기록되어 있는 테이블의 데이터가 너무 방대했습니다. 로그인 기록 뿐 아니라 기타 하나원큐 고객들의 모든 활동 내역이 저장되어 있었기 때문에, 최종 로그인 기록을 SELECT하는 과정에서 많은 시간이 소요되었습니다.
이를 개선하기 위해 해당 테이블 개요를 살펴보니 테이블 날짜에 따라 분기별로 Range Partition이 생성되어 있는 것을 알 수 있었습니다. 기존 쿼리의 실행계획을 살펴보니 Full Table Scan이 이루어 지고 있었기 때문에 WHERE조건 내에 Range Partition Key로 잡힌 컬럼의 범위 조건을 추가하여 Partition Range로 조회 범위를 줄여 SQL 실행 시간을 단축시켰습니다.
파티션의 종류는?
① RANGE : 범위 기준으로 분할 ② LIST : 특정 값들의 집합으로 분할 ③ HASH ④ INTERVAL ⑤ REFERENCE
RANGE
- 날짜나 숫자 처럼 범위를 가진 데이터(연속된 값)를 기준으로 하여 만든 파티션 테이블입니다.
- 함께 저장되어야 할 데이터의 범위를 지정하여 테이블을 파티션 합니다.
- Column Value의 범위를 기준으로 하여 행을 분할하는 형태입니다.
SQL> CREATE TABLE range_partition
(
range_key_column date NOT NULL,
data varchar2(20)
)
PARTITION BY RANGE ( range_key_column )
(
PARTITION part_1 VALUES LESS THAN ( to_date('01/01/2022','dd/mm/yyyy')),
PARTITION part_2 VALUES LESS THAN ( to_date('01/01/2023','dd/mm/yyyy'))
)
Table created.
LIST
- 특정값을 가진 데이터로 만든 파티션 테이블입니다.
- 데이터가 균등하게 분포되어 있어 데이터 분포도가 낮지 않을때 유용합니다.
- 이산 값들을 집합으로 묶어 함께 저장될 데이터를 결정하기 때문에 다중 컬럼을 지원하지 않고 단일 컬럼만 가능합니다.
- 해시 파티션은 데이터가 어느 파티션에 지정될지 알 수 없기 때문에 관리의 목적보다는, 데이터를 분산시켜 디스크 성능을 개선하는데 목적을 두고 있습니다.
INTERVAL
- Range 파티션과 유사하며 파티션이 추가되는 기준(규칙)을 지정할 때 사용합니다. - 기존 파티션에 데이터가 있고 새로운 데이터가 입력될 때에만 새로운 파티션을 생성합니다. - Range 파티션에서 MAXVALUE 파티션 지정 없이 생성한 경우, 후에 데이터가 추가됐을 때 지정한 INTERVAL 만큼의 범위를 가지는 파티션이 생성됩니다.
REFERENCE
- 자식 테이블 파티션이 부모 테이블 파티션과 일대일 관계인 환경에서 자식 테이블을 파티션할 때 사용합니다. - 자식 테이블의 파티셔닝을 부모 테이블로부터 상속받습니다. - 파티셔닝 키는 자식 테이블의 실제 컬럼에 저장되지 않습니다.
결론부터 말씀드리면 아닙니다! DML처리를 하려는 컬럼이 INDEX 컬럼이냐 아니냐에 따라 성능차이가 달라집니다.
또한 DML 처리건수가 많지 않을 때에는 사용자가 느끼지 못할만큼 성능 저하에 끼치는 영향이 아주 미미하다고 합니다.
그럼 왜 테이블에 INSERT가 잦으면 인덱스 성능이 저한된다고 하는 걸까요?
테이블은 힙구조인데 반해, 인덱스는 클러스터형이기 때문입니다.
- 테이블 : 정렬이 안된 힙구조의 데이터 집합 - 인덱스 : 클러스터링된 열을 사용하여 사용자 정의 열 정렬 순서가 있는 데이터 집합
아래 그림을 보시면 이해가 쉬울 것 같습니다! 일반 테이블과 인덱스 테이블의 차이가 보이시나요?
가장 왼쪽의 테이블이 바로 클러스터링 되지 않은 기본 테이블입니다. 내용을 보시면 데이터들이 뒤죽박죽 입력한 순서대로 정렬되어 있는 것을 알 수 있습니다. 이때 INSERT 하게 되면 남은 빈공간에 순서 상관없이 데이터를 추가만 하면 되기 때문에 성능저하와 관련이 없습니다.
반면, 오른쪽 두 개의 Clustered 테이블을 보시면 예쁘게 정렬되어 있는 것을 볼 수 있습니다. 이게 바로 인덱스 테이블 구조라고 보시면 됩니다. 이때, 새로운 데이터를 INSERT하게 되면, 정렬 순서에 맞는 빈 공간을 찾아 추가해야 하기 때문에 성능의 저하를 가져올 수 밖에 없습니다.
심지어 데이터를 추가할 빈 공간이 없다면? 기존 블록의 내용 중 일부를 새 블록에 기록한 후 기존 블록에 빈 공간을 만들어서 새로운 데이터를 추가해야하는 INDEX Split 현상이 발생하기 때문에 속도가 느려질 수 밖에 없게 됩니다.
DELETE와 UPDATE도 똑같은 이유로 인덱스의 성능저하를 가져올까요?
아닙니다. 우선 DELETE부터 설명해드리자면, 테이블에 DELETE가 발생해도 인덱스는 삭제되지 않습니다. 즉, 테이블 데이터는 삭제되어도 인덱스 테이블에는 그 내용이 그대로 남게 되는 거죠. 그래서 테이블 데이터는 1만건밖에 없어도, 인덱스 테이블에는 10만건의 데이터가 남아있을 수 있기 때문에 성능 저하는 가져온다고 말하는 것입니다.
UDPATE의 경우는 어떨까요? 사실 인덱스에는 UDPATE의 개념이 없습니다. 그래서 만약 테이블에 UPDATE가 발생한다면, 인덱스에서는 [DELETE → INSERT] 즉, 두 번의 DML이 이루어지게 됩니다. 그래서 UDPATE는 INSERT, DELETE보다 2배의 작업이 수행되기 때문에 가장 부하가 크다고 볼 수 있습니다.
그럼 DML이 자주 발생한 INDEX는 어떻게 관리해야 할까?
인덱스는 한번 만들어 놓는다고 해서 영구적으로 잘 사용할 수 있는 것이 아니라 데이터의 insert, delete, update 등을 통하여 성능이 저하되기 때문에, 인덱스를 지속적으로 사용하기 위해서는 꾸준한 관리가 필요하다고 합니다. 이를 바로 '인덱스 리빌드'라고 합니다. 저는 DBA가 아니기 때문에 해당 작업을 할 일은 없을 것 같아서 타 블로그 링크로 대체합니다! 자세한 내용이 궁금하신 분들은 아래 블로그를 참고해보세요^^~
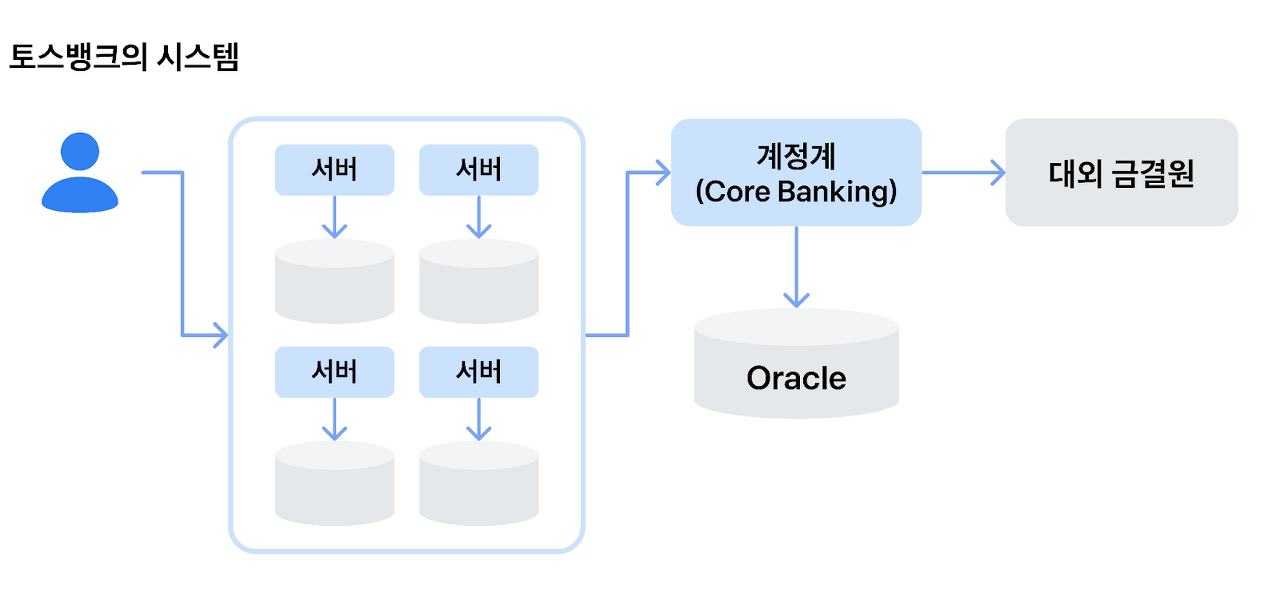
MSA 아키텍처를 채택한 토스뱅크 계정계(코어뱅킹)는 '여신/수신/외환' 등 고유의 업무 영역마다 서버와 데이터베이스가 별도로 분리되어 있다고 합니다. 서로 다른 서버를 사용하고 있기 때문에 '외환☞여신'과 같이 다른 업무 영역끼리 호출할 때에는 시스템간에는 직접적인 호출이 아닌 'HTTP API' 등의 통신을 통해서 타팀 서비스를 호출하고 있다고 합니다.
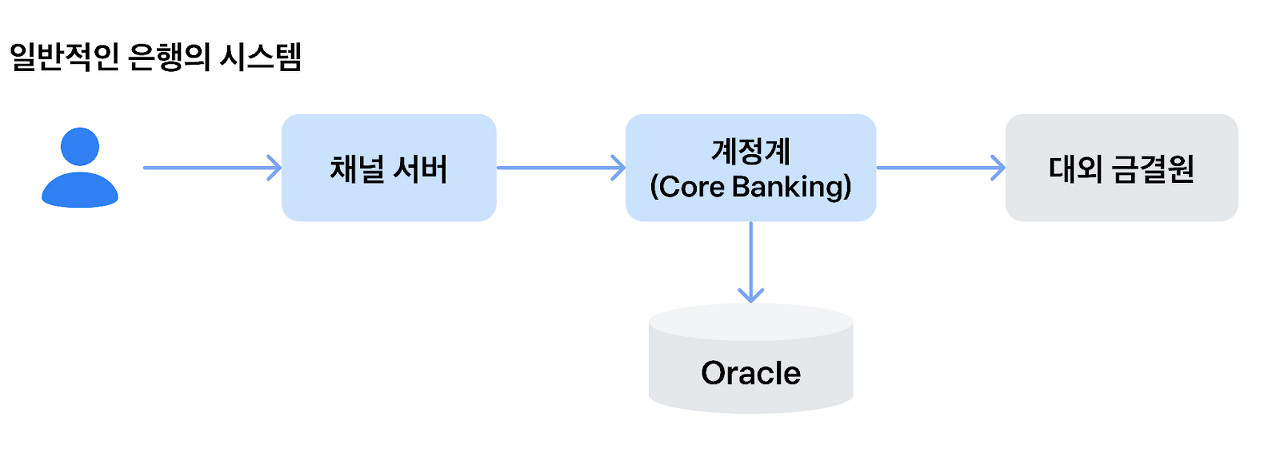
반면 전통적인 시중은행 계정계는 '여신/수신/외환' 등 계정계 내의 업무 팀들이 모두 동일한 서버, 동일한 데이터를 사용하고 있습니다. 따라서 자신의 서비스에서 타팀 모듈을 호출할 때에, 별도의 통신없이 직접 타팀 서비스를 호출하는 참조 방식을 택하고 있습니다.
토스뱅크는 왜 코어뱅킹을 MSA로 전환했을까요?
토스뱅크가 시중은행이 수십년간 안정적으로 운영되고 있는 전통 계정계 방식을 MSA방식으로 전환하기로 한 계기는 크게 아래 두 가지 이유가 있다고 합니다.
① 트래픽 몰림으로 인한 성능저하 문제를 해결하기 위해 ② 잦은 변경과 배포에도 쉽게 대응하기 위해
갑자기 사용자가 몰려 트래픽이 증가했을때 트래픽양을 감당하지 못해 시스템이 마비되는 경우가 있습니다. 이때 모놀리식 시스템은 유연하게 스케일아웃하고 다른 서비스의 장애로 이어지는 것을 막기 힘든 구조입니다.하나의 거대한 덩어리구조이기 때문에 서로의 서비스 내의 타팀의 모듈이 복잡하게 엮여있기 있기 때문입니다. 하지만 MSA 아키텍쳐 내에서는 사람들이 몰릴 특정 업무 서버에서만 유량제어를 처리하면 되기 때문에 성능 저하 문제를 쉽게 해결할 수 있다고 합니다.
MSA구조의 계정계, 실제로 어떻게 개발되어 있을까?
실제로 토스뱅크의 '지금 이자 받기' 서비스가 MSA구조로 시스템을 구성하여 매일 70만명 이상의 고객이 몰려도 트래픽 마비 현상을 대비했다고 합니다.
기존 : 한 개의 트랜젝션 내에서 모두 진행 현재 : 별도의 트랜젝션으로 통신
기존 모놀리식 구조 내에서는 한 트랜젝션 내에서 '고객 정보 조회 → 금리조회 → 이자계산 → 이자 송금 → 회계처리' 순으로 모든 비즈니스 로직을 순차적으로 처리하는 방식을 따릅니다.
하지만 토스뱅크의 새로운 코어뱅킹 아키텍처에서는 트랜잭션으로 묶지 않아도 되는 도메인은 별도의 마이크로 서버를 구성하여, 각 서버의 API 호출을 통해 비즈니스 의존성을 느슨하게 가져가도록 구성했다고 합니다. 즉 이자지급용 고객 금리조회용 서버, ⇄ 이자의 회계처리 용 회계 정보 조회용 서버 ⇄ 세금 DML처리용 서버가 서로 통신하는 방식인거죠.
기술스택으로는 토스뱅크의 채널계와 같이 쿠버네티스 위에 스프링 부트, 코틀린, JPA 등을 기반으로 개발했고, 비동기 메시지 처리와 캐싱은 카프카와 레디스를 채택했다고 합니다.
트랜젝션 처리는 어떻게 했을까?
시중은행 계정계 서비스는 보통 하나의 트랜젝션(1-TX) 로 이루어져 있기 때문에 거래가 발생하다가 중간에 에러가 났을 경우, 전체 DML을 Rollback하고 있습니다. 하지만 토스뱅크 계정계의 MSA 구조 내에서는 여러 서버가 통신하며 거래가 이루어지기 때문에 트랜젝션 원자성을 보장하기 어려울 것이란 생각이 들었습니다. 하지만 자체적 기술을 통해 이러한 트랜젝션 문제를 해결했다고 합니다.
① 계좌 단위 현재 잔액 데이터에 대해서만 고유한 로우 락킹(row locking)이 걸리도록 개발해 동시성을 보장 ② 동시성이 발생했을 때 거래를 끝날 때까지 기다릴 수 있도록 재시도할 수 있는 로직과 타임아웃을 적용
이러한 개발 방식으로 고객관점에서 서비스를 사용하면서 락(Lock)이 걸렸다고 느끼지 못하도록 안정적으로 서비스를 구현했다고 합니다.
시중은행의 모놀리식 시스템, 무조건 바꿔야 하는 걸까?
아닙니다. 모놀리식 시스템에 단점만 존재한다면 이렇게 오랫동안 유지된 이유가 없었겠죠?
토스뱅크는 생겨난지 얼마되지 않은 신생 은행입니다. 반면, 현 시중은행들은 인터넷, 스마트뱅킹이 비교적 최근에 생겨났을 뿐 그 역사가 매우 길고 복잡합니다. 개발 시스템도 은행의 역사와 함께 발전해왔기 때문에 수많은 히스토리가 축적되어 있습니다.
이러한 구조 내에서 모놀리식 시스템은 가장 효율적인 유지/보수가 가능한 구조라 생각합니다. 개발자가 트랜젝션에 대한 고려를 하지 않아도 되기 때문에 개발 방식이 MSA 구조에 비해 단순합니다. 단일 서버이기 때문에 리소스 낭비도 적다는 장점이 존재합니다.
또한, 금융은 고객의 돈을 다루는 산업인만큼 '안정성'이 가장 중요합니다. 섣불리 시스템을 변경하였다가 다른 서비스까지 영향을 주는 사고가 발생하기 쉽기 때문에 토스뱅크보다 신중하고 길게 검토하고 접근해야 합니다. 이는 곧 시중은행이 기존 아키텍처를 MSA구조로 바꾼다면 토스뱅크보다 더 많은 비용과 시간이 든다는 뜻이겠죠?
하지만 모놀리식 시스템의 한계점 또한 분명히 존재하기 때문에 작은 신규 서비스부터 MSA 구조로 바꿔나간다면 증가하는 모바일 고객에 대비할 수 있을 것이라 생각합니다.
여기까지, 토스뱅크의 사례를 통해 은행 계정계의 기술 이슈에 대해 공유해드렸습니다. 혹시 잘못된 내용이 있거나 더 듣고 싶은 내용이 있다면 언제든 연락 주세요📞
오늘은 최근 은행 계정계의 핫이슈! 바로 모놀리식 아키텍처와 MSA 아키텍처에 대해서 설명해 드리겠습니다.
토스뱅크 계정계는 시중은행과 무엇이 다를까?
토스뱅크는 계정계 아키텍처를 '모놀리식' 방식에서 '마이크로 서비스' 방식으로 변경하고 있다고 합니다.
모놀리식 아키텍처는 과거부터 시중 모든 은행이 택하고 있는 방식인대요~ 먼저 '모놀리식'과 'MSA' 아키텍처가 대체 무엇인지부터 설명을 드려야겠죠? 아래에서 차근차근 알기 쉽게 설명드릴게요!
모놀리식(Monolithic) 아키텍처란?
모놀리식 아키텍처란 말 그대로 '단단히 하나의 구조로 짜여 있는 아키텍처'를 의미합니다. 즉, 1개의 서버, 1개의 데이터베이스(DB)만을 사용하는 시스템 아키텍처입니다.
이러한 모놀리식 아키텍처 내에서는 전통적인 개발 모델로 하나의 코드 안에 여러 개의 비즈니스 로직이 녹여져 있는 구조를 취합니다.
현재 하나원큐에서 채택하고 있는 계정계 서비스도 대부분 모놀리식으로 구성되어 있어서 이해하기 쉽게 한 가지 예를 설명드리겠습니다.
모놀리식 구성 예시 : 하나원큐 메인 계좌 목록 조회 서비스
하나원큐에 로그인하시면 스와이핑으로 넘겨가면서 계좌를 확인할 수 있는대요~ 이때, 이 계좌 목록을 가져오는 서비스 안에는 크게 세 가지 비즈니스 로직이 하나의 서비스 안에 존재하고 있습니다.
① 수신팀에 등록된 계좌 목록 조회 ② 오픈뱅킹에 등록된 계좌 목록 조회 ③ 전자금융팀에 등록된 돈통 잔액 조회
바로 이렇게 하나의 트랜젝션 안에 다양한 비즈니스 로직이 뭉쳐져 있는 구조를 모놀리식 아키텍처 방식이라고 합니다.
MSA(마이크로 서비스 아키텍처)란?
하나의 거대한 '모놀리식' 아키텍처와 반대로 '마이크로 서비스(Micro Services)'는 독립된 작은 서비스들로 구성된 아키텍처 방식입니다. MSA구조 내에서 독립된 각각의 서비스는 각자 하나의 기능을 수행하고, 서로 구조적으로 정의된 인터페이스(API)를 통해 다른 서비스와 통신합니다.
위의 그림에서 보듯이 각 기능에 따라 DB와 서버가 별도로 존재하는 구조를 일컫습니다. 하나의 기능을 위해서 다양한 서비스가 필요한 경우, 잘게 쪼개진 서비스들이 소통하며 트랜젝션이 이루어지는 것을 말합니다. 현실적으로 각각의 기능에 따라 필요한 DB의 종류, 개발언어, 프레임워크의 종류가 모두 상이할 수밖에 없습니다. 이때 MSA아키텍처 내에서는 각각의 기능이 각각의 필요에 따른 서버와 DB를 구축하게 됩니다.
안녕하세요! 오늘은 은행 IT 시스템이 어떻게 구성되어 있는지에 대해서 은행의 기초적인 시스템 구성에 대해서 설명해 드리겠습니다.
은행 IT의 구성 : 계정계 / 채널계 / 정보계
은행 IT를 검색하시면 가장 먼저 접하게 될 용어는 바로 ‘계정계, 채널계, 정보계’ 일 것입니다. 과연 이게 무엇인지… 처음 들으신 분들은 감이 안 오시죠? 아래에서 하나하나 자세하게 설명드리겠습니다.
1. 계정계(코어뱅킹)
은행 IT의 근본이라고 할 수 있는 코어뱅킹, 즉 ’계정계’부터 설명드리겠습니다.
은행 IT 시스템은 코어뱅킹(계정계)라고 불리는 핵심 시스템이 존재하고 있습니다. 코어뱅킹(계정계) 시스템은 백엔드의 일종이라고 볼 수 있습니다. 즉 서버단에서 ‘여신, 수신, 펀드’ 같은 은행 업무들이 처리되는 로직 영역을 담당합니다.
계정계가 무엇인지 이해하기 쉽게 설명해 드리자면, 인터넷뱅킹과 뱅킹앱이 생겨나기 이전의 은행으로 거슬러 올라가야 합니다.
인터넷 뱅킹이 출범하기 이전에도 은행은 있었습니다. 그때의 은행 IT 시스템은 대체 무슨 용도였을까요?
바로 영업점 은행원들이 사용하는 전산 시스템이 제대로 돌아가게 하기 위함이었습니다. 지금도 은행 영업점에 방문하시면 은행원들이 컴퓨터를 활용해 업무를 처리하는 것을 볼 수 있습니다.
은행 영업점에서는 고객들이 계좌를 개설하고, 적금 상품에 가입하고, 대출을 받는 등 수많은 은행 업무들이 처리됩니다. 이러한 일들이 단순 서류 작업으로 진행될 수 없겠죠?
이때 은행 영업점에서 은행원들이 업무를 처리할 때 사용하는 컴퓨터 프로그램 명칭이 바로 ‘계정단말(통합단말)’입니다.
즉, ‘계정계’란 과거부터 은행 업무의 로직을 처리하고 있는 전산 시스템이라고 볼 수 있습니다.
계정계는 복잡한 은행 업무 로직을 처리하는 시스템이기 때문에 업무의 종류에 따라 팀들이 세분화되어 있습니다. 구체적으로 ‘여신개발팀, 수신개발팀, 외환팀’ 들이 존재합니다.
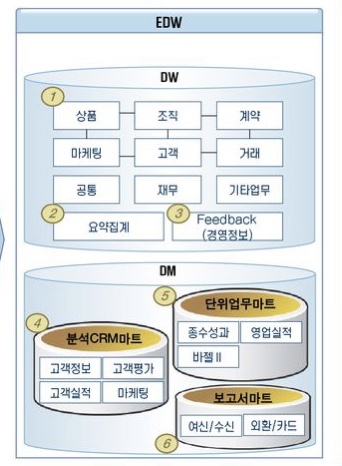
2. ‘정보계’란?
정보계란 데이터베이스(DB)를 관리하는 팀입니다.
은행에서는 DB테이블을 ‘원장’이라고 표현하는데요~ 은행 원장에는 정말 데이터가 담겨있습니다. 은행 DB에는 수많은 고객들의 고객정보 뿐만 아니라 계좌정보, 대출정보, 입금/출금 거래내역 등 하루에도 돈과 관련된 데이터가 수십만건씩 쌓이고 있습니다.
따라서 이런 데이터가 제대로 관리되기 위해서는 안정적인 DB 시스템이 필요합니다. 정보계는 이런 방대한 데이터가 안정적으로 보관되고 유실되지 않도록 하기 위한 데이터베이스 시스템을 구성하는 부문입니다.
뿐만 아니라 방대한 데이터를 가지고 다양한 고객 마케팅 정보를 분석하고 영업 인사이트를 도출할 수 있습니다. 정보계에서는 단순히 데이터베이스 관리 뿐 아니라 대용량 데이터를 분석하는 업무도 담당합니다. 또한 최근들어 중요해진 빅데이터 시스템을 구성 및 관리하는 업무 또한 ‘정보계’에서 관리하게 됩니다.
이 원장에 적합한 데이터를 넣고 조회하는 등의 DML업무는 ‘계정계’에서 담당하지만, 이 거대한 원장 테이블을 만들고(DDL) 각 업무팀에 맞게 원장의 접근 권한을 제어(DCL)하는 업무는 ‘정보계’에서 담당하게 됩니다.
또 데이터 베이스에 사용될 표준 용어(메타)관리, 데이터 베이스 조회 속도를 개선하는 튜닝 등의 작업도 모두 ‘정보계‘에서 수행하게 됩니다.
3. 채널계
채널계는 어렵지 않습니다. 바로 여러분이 사용하는 뱅킹앱, 인터넷뱅킹을 개발하는 시스템이라고 보면 되기 때문입니다.
은행이 영업점에서 처리하는 대면 서비스보다 스마트폰과 인터넷을 통해 처리하는 '비대면 서비스'가 중시되면서 채널계의 영역은 점점 커지고 있는 추세입니다.
과거의 은행 채널계는 폰뱅킹(텔레뱅킹), ATM 등의 고객과 접하는 계층을 모두 포괄했지만 요즘 은행에서 채널계라고 하면 '인터넷뱅킹, 스마트폰뱅킹' 영역만을 지칭하고 있다고 볼 수 있습니다.
인터넷 은행의 등장으로 인해 시중은행에서 이 채널계의 비중이 점점 커지고 있습니다.
채널계 개발자들은 사용자들이 직접 사용하는 화면단을 개발합니다. 이 영역을 PT(Presentaion-Tier)라고 합니다. 이외에도 사용자들이 보이지 않는 영역을 처리하는 BT(Business-Tier)도 존재하는데, 자세한 내용은 아래 게시글에 작성되어 있으니 한 번 확인해 보세요 😉