꼭 알아야 하는 트랜잭션의 특징 하나만 기억하자면, 한 거래(트랜잭션) 내에 작업 전체가 실패하거나 성공하는 하나의 작업으로 묶는다는 점입니다.
실패한 트랜잭션 : A고객의 계좌이체
① 출금 계좌 목록 SELECT → 성공 ② 출금 계좌 잔액 UPDATE → 성공 ③ 출금 거래 기록 INSERT → 성공 ④ 입금 거래 처리(당행이체/타행이체) → 실패 : 작업 전체 ROLLBACK ⑤ 입금 거래 기록 INSERT
성공한 트랜잭션 : B고객의 계좌이체
① 출금 계좌 목록 SELECT → 성공 ② 출금 계좌 잔액 UPDATE → 성공 ③ 출금 거래 기록 INSERT → 성공 ④ 입금 거래 처리(당행이체/타행이체) → 성공 ⑤ 입금 거래 기록 INSERT → 성공 : 작업 전체 COMMIT
만약 출금 거래까지만 INSERT가 되고 입금 거래내역이 INSERT 되지 않는다면, 거래 내역의 부정확한 데이터들이 생겨나겠죠? 그래서 한 거래 내에서는 1개의 작업이라도 실패하면 전체 DB를 다 Rollback 처리하고, 모든 작업이 성공해야만 DB Commit을 진행해야 합니다.
만약 계좌이체 진행 중에 다른 스레드 요청이 들어오면 어떻게 될까?
A고객의 거래이체 트랜잭션이 끝나기 전에 B고객의 계좌이체 요청이 들어온 경우를 가정해 봅시다. A고객의 요청이 먼저 들어왔으니, B의 요청은 A가 끝날 때까지 대기해야 할까요? 아닙니다! 보통 동시에 요청이 들어오면, 각 트랜젝션은 동시에 처리됩니다.
하지만 트랜잭션이 동시에 처리 가능한 개수를 지정해두지 않으면 서버가 과부하 걸려 죽을 수밖에 없겠죠? 그래서 스프링을 생각해 보면, 톰캣 WAS 내에 구현된 스레드풀에 의해서 요청의 갯수가 제어됩니다. Default로 200개의 쓰레드 요청을 허용한다고 하니 아래 내용을 참고해 보세요!
동시에 발생한 거래 - A고객 : 2번 계좌에서 1번 계좌로 100원 입금 (1번 : 500원 → 600원 / 2번 : 1000원 → 900원 ) - B고객 : 1번 계좌에서 2번 계좌로 800원 입금 (1번 : 500원 → -300원 / 2번 : 1000원 → 1800원 )
과연 두 거래가 동시에 처리된다면, DB 내에 거래 잔액이 어떻게 될까요?
1번계좌
2번계좌
최근 거래 후 잔액
500원
1000원
A고객, B고객 잔액조회 (동시)
500원
1000원
A고객 출금 (2번 → 1번 : 100원)
500 + 100 = 600원
1000 - 100 = 900원
B고객 출금 (1번 → 2번 : 800원)
500 - 800 = -300원
1000 + 800 = 1800원
C고객 잔액조회
-300원
1800원
C고객이 잔액을 조회했을 때, B고객이 출금한 이후에 잔액만 볼 수 있겠죠? A고객이 계좌이체한 내역은 DB에 남아있지 않겠죠? 그래서 필요한 것이 바로 DB Lock입니다!
DB Lock이 뭘까?
DB Lock이란 데이터베이스는 여러 사용자들이 같은 데이터를 동시에 접근하는 상황에서, 데이터가 어긋나지 않도록 DB를 보호하는 방법입니다!
위의 상황에서 A와 B고객이 똑같은 데이터를 읽어가는 일이 발생하지 않도록 계좌 잔액이 기록된 테이블에 Lock을 걸어둔다면, 두 트랜젝션이 동시에 들어와도 0.00001초라도 먼저 요청한 고객이 테이블을 읽고 있다면, 다른 요청이 들어와도 테이블 SELECT가 되지 않아 잔액이 틀어지지 않게 되는 거죠!
DB Lock을 설정할 수 있는 범위는?
일반적으로는 Table Lock과 Row Lock을 주로 접하게 됩니다. 데이터베이스 전체, 파일, 블록, 컬럼 단위로도 Lock을 걸 수 있지만 실무에서 본 기억은 없습니다.
테이블 락(Table Lock)
테이블 수준의 Lock은 테이블을 기준으로 Lock을 설정합니다.
이는 테이블의 모든 행을 업데이트 하는 등의 전체 테이블에 영향을 주는 변경을 수행할 때 유용합니다.
주로 DDL(create, alter, drop 등) 구문과 함께 사용되며 DDL Lock이라고도 합니다.
DB Lock은 크게 공유(Shared) Lock과 베타(Exclusive), 업데이트(Update) Lock있습니다.
공유락(Shared Lock) : 읽기 O , 쓰기 X ① 공유 Lock은 데이터를 읽을 때 사용되며, Read Lock이라고도 불립니다. ② 공유 Lock은 공유 Lock 끼리는 동시에 접근이 가능합니다. 즉, 하나의 데이터를 읽는 것은 여러 사용자가 동시에 할 수 있다라는 것입니다. ③ 공유 Lock이 설정된 데이터에 베타 Lock을 사용할 수는 없습니다.
베타락(Exclusive Lock) : 읽기 X , 쓰기 X ① 베타 Lock은 데이터를 변경하고자 할 때 사용되며 Write Lock이라고도 불립니다. ② 베타 Lock은 트랜잭션이 완료될 때까지 유지됩니다. 베타락은 Lock이 해제될 때까지 다른 트랜잭션(읽기 포함)은 해당 리소스에 접근할 수 없습니다. ③ 베타 Lock이 걸려있다면 다른 트랜잭션은 공유 락, 배타 락 둘 다 획득 할 수 없습니다. 업데이트락(Update Lock) U-Lock 잠금이 걸려 있어도 S-Lock만은 걸 수 있다 정도로 알면 될것 같습니다. https://resisa.tistory.com/m/184
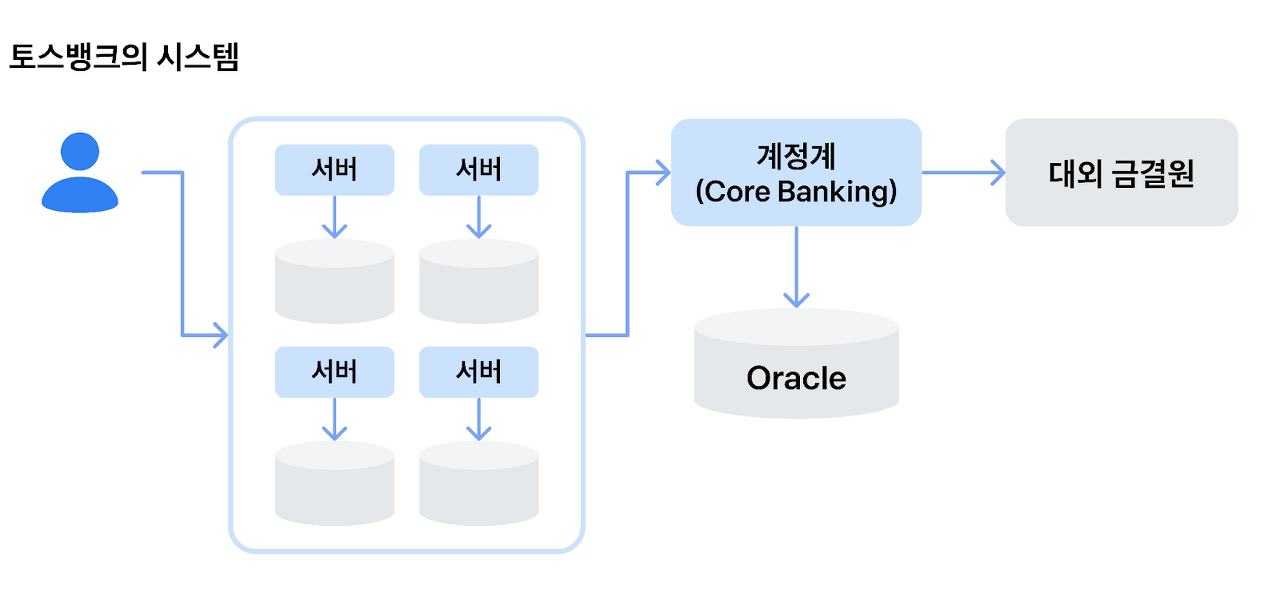
MSA 아키텍처를 채택한 토스뱅크 계정계(코어뱅킹)는 '여신/수신/외환' 등 고유의 업무 영역마다 서버와 데이터베이스가 별도로 분리되어 있다고 합니다. 서로 다른 서버를 사용하고 있기 때문에 '외환☞여신'과 같이 다른 업무 영역끼리 호출할 때에는 시스템간에는 직접적인 호출이 아닌 'HTTP API' 등의 통신을 통해서 타팀 서비스를 호출하고 있다고 합니다.
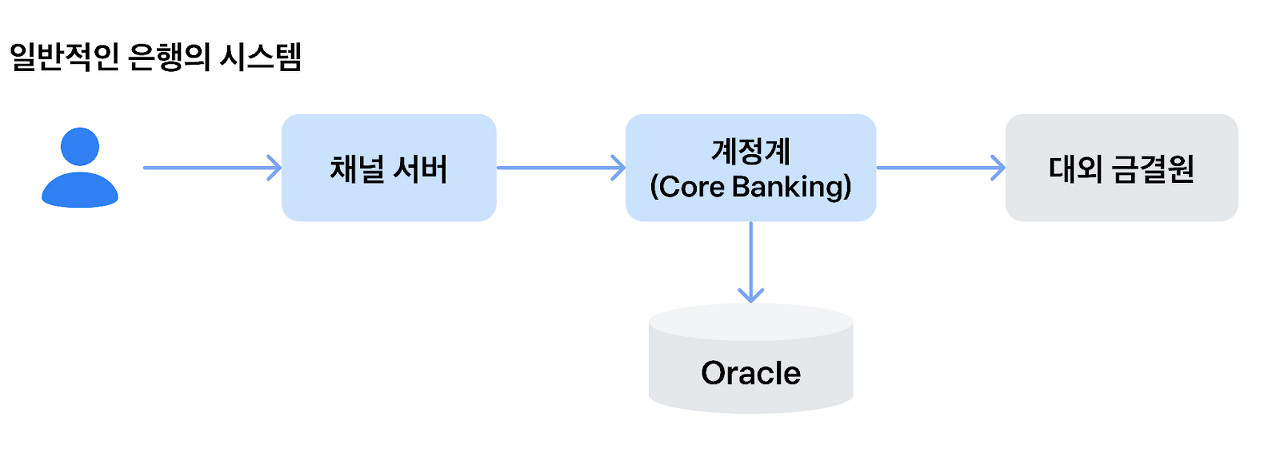
반면 전통적인 시중은행 계정계는 '여신/수신/외환' 등 계정계 내의 업무 팀들이 모두 동일한 서버, 동일한 데이터를 사용하고 있습니다. 따라서 자신의 서비스에서 타팀 모듈을 호출할 때에, 별도의 통신없이 직접 타팀 서비스를 호출하는 참조 방식을 택하고 있습니다.
토스뱅크는 왜 코어뱅킹을 MSA로 전환했을까요?
토스뱅크가 시중은행이 수십년간 안정적으로 운영되고 있는 전통 계정계 방식을 MSA방식으로 전환하기로 한 계기는 크게 아래 두 가지 이유가 있다고 합니다.
① 트래픽 몰림으로 인한 성능저하 문제를 해결하기 위해 ② 잦은 변경과 배포에도 쉽게 대응하기 위해
갑자기 사용자가 몰려 트래픽이 증가했을때 트래픽양을 감당하지 못해 시스템이 마비되는 경우가 있습니다. 이때 모놀리식 시스템은 유연하게 스케일아웃하고 다른 서비스의 장애로 이어지는 것을 막기 힘든 구조입니다.하나의 거대한 덩어리구조이기 때문에 서로의 서비스 내의 타팀의 모듈이 복잡하게 엮여있기 있기 때문입니다. 하지만 MSA 아키텍쳐 내에서는 사람들이 몰릴 특정 업무 서버에서만 유량제어를 처리하면 되기 때문에 성능 저하 문제를 쉽게 해결할 수 있다고 합니다.
MSA구조의 계정계, 실제로 어떻게 개발되어 있을까?
실제로 토스뱅크의 '지금 이자 받기' 서비스가 MSA구조로 시스템을 구성하여 매일 70만명 이상의 고객이 몰려도 트래픽 마비 현상을 대비했다고 합니다.
기존 : 한 개의 트랜젝션 내에서 모두 진행 현재 : 별도의 트랜젝션으로 통신
기존 모놀리식 구조 내에서는 한 트랜젝션 내에서 '고객 정보 조회 → 금리조회 → 이자계산 → 이자 송금 → 회계처리' 순으로 모든 비즈니스 로직을 순차적으로 처리하는 방식을 따릅니다.
하지만 토스뱅크의 새로운 코어뱅킹 아키텍처에서는 트랜잭션으로 묶지 않아도 되는 도메인은 별도의 마이크로 서버를 구성하여, 각 서버의 API 호출을 통해 비즈니스 의존성을 느슨하게 가져가도록 구성했다고 합니다. 즉 이자지급용 고객 금리조회용 서버, ⇄ 이자의 회계처리 용 회계 정보 조회용 서버 ⇄ 세금 DML처리용 서버가 서로 통신하는 방식인거죠.
기술스택으로는 토스뱅크의 채널계와 같이 쿠버네티스 위에 스프링 부트, 코틀린, JPA 등을 기반으로 개발했고, 비동기 메시지 처리와 캐싱은 카프카와 레디스를 채택했다고 합니다.
트랜젝션 처리는 어떻게 했을까?
시중은행 계정계 서비스는 보통 하나의 트랜젝션(1-TX) 로 이루어져 있기 때문에 거래가 발생하다가 중간에 에러가 났을 경우, 전체 DML을 Rollback하고 있습니다. 하지만 토스뱅크 계정계의 MSA 구조 내에서는 여러 서버가 통신하며 거래가 이루어지기 때문에 트랜젝션 원자성을 보장하기 어려울 것이란 생각이 들었습니다. 하지만 자체적 기술을 통해 이러한 트랜젝션 문제를 해결했다고 합니다.
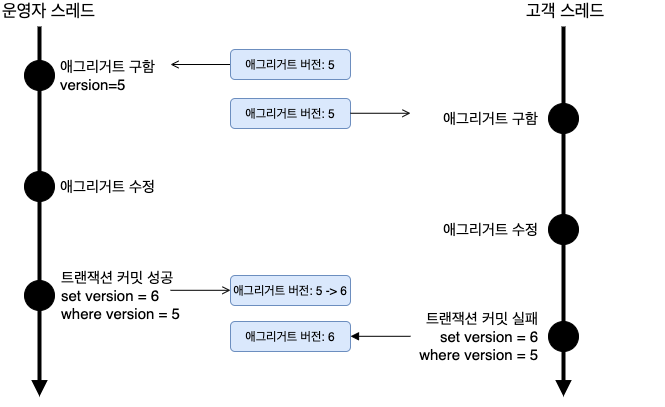
① 계좌 단위 현재 잔액 데이터에 대해서만 고유한 로우 락킹(row locking)이 걸리도록 개발해 동시성을 보장 ② 동시성이 발생했을 때 거래를 끝날 때까지 기다릴 수 있도록 재시도할 수 있는 로직과 타임아웃을 적용
이러한 개발 방식으로 고객관점에서 서비스를 사용하면서 락(Lock)이 걸렸다고 느끼지 못하도록 안정적으로 서비스를 구현했다고 합니다.
시중은행의 모놀리식 시스템, 무조건 바꿔야 하는 걸까?
아닙니다. 모놀리식 시스템에 단점만 존재한다면 이렇게 오랫동안 유지된 이유가 없었겠죠?
토스뱅크는 생겨난지 얼마되지 않은 신생 은행입니다. 반면, 현 시중은행들은 인터넷, 스마트뱅킹이 비교적 최근에 생겨났을 뿐 그 역사가 매우 길고 복잡합니다. 개발 시스템도 은행의 역사와 함께 발전해왔기 때문에 수많은 히스토리가 축적되어 있습니다.
이러한 구조 내에서 모놀리식 시스템은 가장 효율적인 유지/보수가 가능한 구조라 생각합니다. 개발자가 트랜젝션에 대한 고려를 하지 않아도 되기 때문에 개발 방식이 MSA 구조에 비해 단순합니다. 단일 서버이기 때문에 리소스 낭비도 적다는 장점이 존재합니다.
또한, 금융은 고객의 돈을 다루는 산업인만큼 '안정성'이 가장 중요합니다. 섣불리 시스템을 변경하였다가 다른 서비스까지 영향을 주는 사고가 발생하기 쉽기 때문에 토스뱅크보다 신중하고 길게 검토하고 접근해야 합니다. 이는 곧 시중은행이 기존 아키텍처를 MSA구조로 바꾼다면 토스뱅크보다 더 많은 비용과 시간이 든다는 뜻이겠죠?
하지만 모놀리식 시스템의 한계점 또한 분명히 존재하기 때문에 작은 신규 서비스부터 MSA 구조로 바꿔나간다면 증가하는 모바일 고객에 대비할 수 있을 것이라 생각합니다.
여기까지, 토스뱅크의 사례를 통해 은행 계정계의 기술 이슈에 대해 공유해드렸습니다. 혹시 잘못된 내용이 있거나 더 듣고 싶은 내용이 있다면 언제든 연락 주세요📞
오늘은 최근 은행 계정계의 핫이슈! 바로 모놀리식 아키텍처와 MSA 아키텍처에 대해서 설명해 드리겠습니다.
토스뱅크 계정계는 시중은행과 무엇이 다를까?
토스뱅크는 계정계 아키텍처를 '모놀리식' 방식에서 '마이크로 서비스' 방식으로 변경하고 있다고 합니다.
모놀리식 아키텍처는 과거부터 시중 모든 은행이 택하고 있는 방식인대요~ 먼저 '모놀리식'과 'MSA' 아키텍처가 대체 무엇인지부터 설명을 드려야겠죠? 아래에서 차근차근 알기 쉽게 설명드릴게요!
모놀리식(Monolithic) 아키텍처란?
모놀리식 아키텍처란 말 그대로 '단단히 하나의 구조로 짜여 있는 아키텍처'를 의미합니다. 즉, 1개의 서버, 1개의 데이터베이스(DB)만을 사용하는 시스템 아키텍처입니다.
이러한 모놀리식 아키텍처 내에서는 전통적인 개발 모델로 하나의 코드 안에 여러 개의 비즈니스 로직이 녹여져 있는 구조를 취합니다.
현재 하나원큐에서 채택하고 있는 계정계 서비스도 대부분 모놀리식으로 구성되어 있어서 이해하기 쉽게 한 가지 예를 설명드리겠습니다.
모놀리식 구성 예시 : 하나원큐 메인 계좌 목록 조회 서비스
하나원큐에 로그인하시면 스와이핑으로 넘겨가면서 계좌를 확인할 수 있는대요~ 이때, 이 계좌 목록을 가져오는 서비스 안에는 크게 세 가지 비즈니스 로직이 하나의 서비스 안에 존재하고 있습니다.
① 수신팀에 등록된 계좌 목록 조회 ② 오픈뱅킹에 등록된 계좌 목록 조회 ③ 전자금융팀에 등록된 돈통 잔액 조회
바로 이렇게 하나의 트랜젝션 안에 다양한 비즈니스 로직이 뭉쳐져 있는 구조를 모놀리식 아키텍처 방식이라고 합니다.
MSA(마이크로 서비스 아키텍처)란?
하나의 거대한 '모놀리식' 아키텍처와 반대로 '마이크로 서비스(Micro Services)'는 독립된 작은 서비스들로 구성된 아키텍처 방식입니다. MSA구조 내에서 독립된 각각의 서비스는 각자 하나의 기능을 수행하고, 서로 구조적으로 정의된 인터페이스(API)를 통해 다른 서비스와 통신합니다.
위의 그림에서 보듯이 각 기능에 따라 DB와 서버가 별도로 존재하는 구조를 일컫습니다. 하나의 기능을 위해서 다양한 서비스가 필요한 경우, 잘게 쪼개진 서비스들이 소통하며 트랜젝션이 이루어지는 것을 말합니다. 현실적으로 각각의 기능에 따라 필요한 DB의 종류, 개발언어, 프레임워크의 종류가 모두 상이할 수밖에 없습니다. 이때 MSA아키텍처 내에서는 각각의 기능이 각각의 필요에 따른 서버와 DB를 구축하게 됩니다.
안녕하세요! 오늘은 은행 IT 시스템이 어떻게 구성되어 있는지에 대해서 은행의 기초적인 시스템 구성에 대해서 설명해 드리겠습니다.
은행 IT의 구성 : 계정계 / 채널계 / 정보계
은행 IT를 검색하시면 가장 먼저 접하게 될 용어는 바로 ‘계정계, 채널계, 정보계’ 일 것입니다. 과연 이게 무엇인지… 처음 들으신 분들은 감이 안 오시죠? 아래에서 하나하나 자세하게 설명드리겠습니다.
1. 계정계(코어뱅킹)
은행 IT의 근본이라고 할 수 있는 코어뱅킹, 즉 ’계정계’부터 설명드리겠습니다.
은행 IT 시스템은 코어뱅킹(계정계)라고 불리는 핵심 시스템이 존재하고 있습니다. 코어뱅킹(계정계) 시스템은 백엔드의 일종이라고 볼 수 있습니다. 즉 서버단에서 ‘여신, 수신, 펀드’ 같은 은행 업무들이 처리되는 로직 영역을 담당합니다.
계정계가 무엇인지 이해하기 쉽게 설명해 드리자면, 인터넷뱅킹과 뱅킹앱이 생겨나기 이전의 은행으로 거슬러 올라가야 합니다.
인터넷 뱅킹이 출범하기 이전에도 은행은 있었습니다. 그때의 은행 IT 시스템은 대체 무슨 용도였을까요?
바로 영업점 은행원들이 사용하는 전산 시스템이 제대로 돌아가게 하기 위함이었습니다. 지금도 은행 영업점에 방문하시면 은행원들이 컴퓨터를 활용해 업무를 처리하는 것을 볼 수 있습니다.
은행 영업점에서는 고객들이 계좌를 개설하고, 적금 상품에 가입하고, 대출을 받는 등 수많은 은행 업무들이 처리됩니다. 이러한 일들이 단순 서류 작업으로 진행될 수 없겠죠?
이때 은행 영업점에서 은행원들이 업무를 처리할 때 사용하는 컴퓨터 프로그램 명칭이 바로 ‘계정단말(통합단말)’입니다.
즉, ‘계정계’란 과거부터 은행 업무의 로직을 처리하고 있는 전산 시스템이라고 볼 수 있습니다.
계정계는 복잡한 은행 업무 로직을 처리하는 시스템이기 때문에 업무의 종류에 따라 팀들이 세분화되어 있습니다. 구체적으로 ‘여신개발팀, 수신개발팀, 외환팀’ 들이 존재합니다.
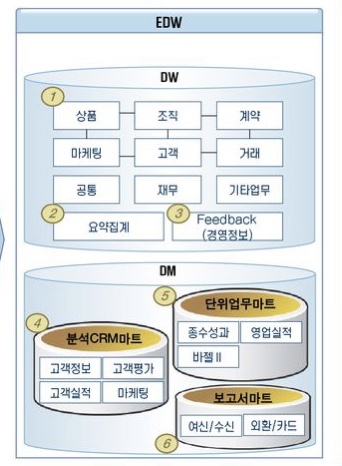
2. ‘정보계’란?
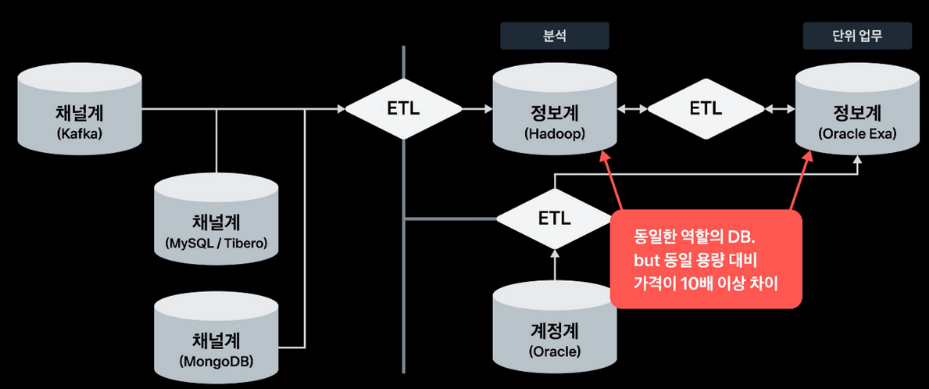
정보계란 데이터베이스(DB)를 관리하는 팀입니다.
은행에서는 DB테이블을 ‘원장’이라고 표현하는데요~ 은행 원장에는 정말 데이터가 담겨있습니다. 은행 DB에는 수많은 고객들의 고객정보 뿐만 아니라 계좌정보, 대출정보, 입금/출금 거래내역 등 하루에도 돈과 관련된 데이터가 수십만건씩 쌓이고 있습니다.
따라서 이런 데이터가 제대로 관리되기 위해서는 안정적인 DB 시스템이 필요합니다. 정보계는 이런 방대한 데이터가 안정적으로 보관되고 유실되지 않도록 하기 위한 데이터베이스 시스템을 구성하는 부문입니다.
뿐만 아니라 방대한 데이터를 가지고 다양한 고객 마케팅 정보를 분석하고 영업 인사이트를 도출할 수 있습니다. 정보계에서는 단순히 데이터베이스 관리 뿐 아니라 대용량 데이터를 분석하는 업무도 담당합니다. 또한 최근들어 중요해진 빅데이터 시스템을 구성 및 관리하는 업무 또한 ‘정보계’에서 관리하게 됩니다.
이 원장에 적합한 데이터를 넣고 조회하는 등의 DML업무는 ‘계정계’에서 담당하지만, 이 거대한 원장 테이블을 만들고(DDL) 각 업무팀에 맞게 원장의 접근 권한을 제어(DCL)하는 업무는 ‘정보계’에서 담당하게 됩니다.
또 데이터 베이스에 사용될 표준 용어(메타)관리, 데이터 베이스 조회 속도를 개선하는 튜닝 등의 작업도 모두 ‘정보계‘에서 수행하게 됩니다.
3. 채널계
채널계는 어렵지 않습니다. 바로 여러분이 사용하는 뱅킹앱, 인터넷뱅킹을 개발하는 시스템이라고 보면 되기 때문입니다.
은행이 영업점에서 처리하는 대면 서비스보다 스마트폰과 인터넷을 통해 처리하는 '비대면 서비스'가 중시되면서 채널계의 영역은 점점 커지고 있는 추세입니다.
과거의 은행 채널계는 폰뱅킹(텔레뱅킹), ATM 등의 고객과 접하는 계층을 모두 포괄했지만 요즘 은행에서 채널계라고 하면 '인터넷뱅킹, 스마트폰뱅킹' 영역만을 지칭하고 있다고 볼 수 있습니다.
인터넷 은행의 등장으로 인해 시중은행에서 이 채널계의 비중이 점점 커지고 있습니다.
채널계 개발자들은 사용자들이 직접 사용하는 화면단을 개발합니다. 이 영역을 PT(Presentaion-Tier)라고 합니다. 이외에도 사용자들이 보이지 않는 영역을 처리하는 BT(Business-Tier)도 존재하는데, 자세한 내용은 아래 게시글에 작성되어 있으니 한 번 확인해 보세요 😉
오늘은 제가 은행 IT에 근무하면서 헷갈렷던 용어인 PT와 BT에 대해서 설명해드리겠습니다.
은행 IT에는 흔히 알고있는 프론트엔드와 백엔드라는 IT 용어를 사용하지 않습니다. 그럼 은행 IT에는 프론트와 백의 영역이 존재하지 않는다고 볼 수 있는 걸까요?
그건 아닙니다! 자세한 내용은 아래에서 설명해드리겠습니다.
은행 IT에는 프론트엔드(FE)와 백엔드(BE)가 존재하지 않을까?
흔히 IT시스템은 프론트엔트(웹, 앱)와 백엔드(서버)로 구성되어 있습니다.
은행도 당연히 타 IT기업들과 같이 자체적으로 웹, 앱(인터넷뱅킹, 스마트폰뱅킹) 시스템을 운영하고 있기 때문에 프론트엔드와 백엔드(서버) 영역이 존재합니다.
다만, 그 은행 IT에서는 FE와 BE를 지칭하는 용어가 조금 다릅니다.
[인터넷뱅킹, 스마트폰뱅킹의 시스템 구성]
프론트엔드(Front-End) ➡️ PT (Presentation-Tier)
백엔드(Back-End) ➡️ BT (Business-Tier)
은행에서는 프론트와 백이라는 용어 대신 PT, BT라는 용어를 사용합니다. 그래서 은행 IT에 입문하시면 PT개발자, BT개발자라는 호칭(?)을 얻게 됩니다. 하지만 은행 IT 시스템은 단순히 PT와 BT의 영역만으로 구성되어 있지 않습니다. 그 이유는 은행에는 뱅킹앱, 인터넷뱅킹만이 존재하는 것이 아니기 때문입니다.
스마트폰이 발달하고 인터넷은행이 설립되며 뱅킹앱을 사용하는 분들이 많아졌지만, 은행은 전통적인 영업점이 큰 비중을 차지하고 있습니다. 따라서 PT, BT는 은행 IT의 일부인 ‘채널계’에 국한되어 존재할 뿐입니다. 다음 게시글 부터는 그 거대한 은행 IT 구성에 대해서 알기 쉽게 전달드리겠습니다.